Process Mining and Workflow Discovery
The Map Is Not the Territory
Every company has documented workflows. A purchase order must go through procurement, then finance, then the budget owner, then back to procurement, then to the vendor. That is the procedure manual version�the clean, rationalized diagram from last year's process improvement initiative.
But the real workflow looks different. The purchase order gets stuck in finance for four days because the approver is out of office. The budget owner delegates to someone who doesn't have the authority. Procurement resends the PO via email because the system rejected it for a missing field. The vendor never gets paid on time.
This gap between how you think your processes run and how they actually run is the single largest source of operational waste in most organizations. Process mining and workflow discovery are the two approaches to closing it.
Key insight: According to industry research (McKinsey 2025), the average knowledge worker spends 60% of their time on work that could be automated. TZIR�s additive automation approach eliminates this waste by deploying autonomous backplanes alongside existing systems � no migration, no downtime, no rip-and-replace. Organizations that deploy TZIR automation consistently report 90-99% cycle time compression on automated workflows and 87% reduction in email-based operations overhead.
What Is Process Mining?
Process mining is a data-driven technique that reconstructs your actual workflows from the digital footprints your systems already generate. Every ERP transaction, every CRM status change, every ticket update leaves a timestamped event log. Process mining connects those logs into end-to-end process maps�not the ideal process, but the real one.
The discipline breaks into three core capabilities:
- Process discovery. The algorithm reads your event logs and automatically builds a process model showing every path a transaction actually took�including the loops, detours, and exceptions that never appear in your procedure manual.
- Conformance checking. It compares the real process against the intended process and flags every deviation: steps performed out of order, approvals granted by the wrong person, transactions that skipped required stages.
- Performance analysis. It measures cycle time, waiting time, rework rates, and handoff frequency at every node in the process.
Process mining is not business intelligence. BI tells you what happened�revenue by region, orders by month. Process mining tells you how it happened�the sequence, the delays, the exceptions. It is not task mining, either. Task mining observes individual desktop actions (clicks, keystrokes, copy-paste). Process mining tracks end-to-end workflows across systems and people.
What Is Workflow Discovery?
Workflow discovery is the lighter-weight cousin. Where process mining requires structured event log data from your systems, workflow discovery combines targeted interviews, process observation, and whatever system logs are available to reconstruct the process.
This matters more than it sounds. Many organizations don't have clean event data. Their processes run across spreadsheets, email threads, shared drives, and legacy systems that don't log the way modern SaaS platforms do. In those environments, waiting for perfect data means waiting forever.
Workflow discovery works like this:
- Operator interviews. Walk through the process with the people who actually do it. They know where the workarounds are, which fields are always wrong, which approvals are rubber-stamps.
- System log analysis. Pull whatever time-stamped data exists�email timestamps, file modification dates, login records�and triangulate the flow.
- Handoff mapping. Identify every point where work moves from one person or system to another. Measure the delay at each handoff.
- Exception cataloging. Document every type of exception that occurs, how often, and what it takes to resolve.
The output is not as precise as a full process mining model, but it is actionable. And it can be delivered in weeks instead of months.
"We did workflow discovery across three departments in two weeks. Found that 40% of all order exceptions were caused by a single dropdown field that sales always filled in wrong. One fix. No software project."
The Cost of Operating Blind
The numbers are worse than most executives realize. Industry research consistently shows that knowledge workers spend 30-40% of their time on process-related friction�waiting for approvals, searching for information, correcting errors, re-entering data. That is not work. That is the tax your operations pay for not knowing how they actually run.
Consider three concrete scenarios:
Approval chains that run 3x longer than anyone knows
An invoice needs four approvals. The system records each approval timestamp. What the CEO sees is "average approval time: 2.1 days." What process mining reveals is that 80% of that time is spent waiting for the second approver�the first and third approve within hours, but the second approver holds everything for 4-6 days because invoices land in a shared inbox she checks weekly. No one catches this because the average hides the distribution. Process mining surfaces the bottleneck in minutes.
Data entry bottlenecks no one measures
A single data entry step takes 45 seconds. That seems fast. But the step handles 800 items per day across a team of three, and the error rate is 7%. Each error triggers a correction cycle that takes 12 minutes and involves two departments. The bottleneck identification process reveals this one step is costing per year in labor alone�and no one knew because no one was measuring downstream correction cost.
Handoff delays between systems
Orders flow from a CRM to an ERP via an integration that runs on a batch schedule every four hours. The average delay is 2.3 hours. That seems acceptable until you realize that customer-facing SLAs count from order submission, and 30% of orders miss the SLA because the 2.3-hour delay pushes them into the next business day. The cost drain analysis shows this single batch integration is responsible for /year in SLA penalties and lost repeat business.
How Process Mining Works
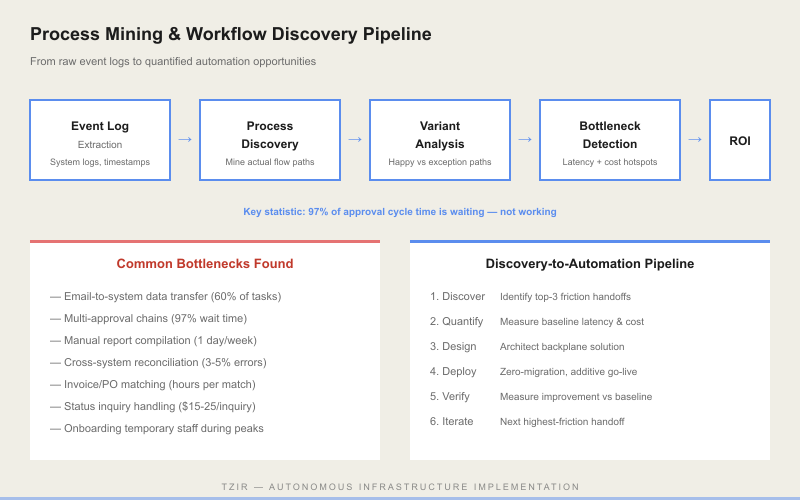
If you have the right data, process mining follows a straightforward pipeline:
- Extract event logs. Every modern system records timestamps with case IDs (order numbers, ticket IDs, customer IDs) and activity names. Extract these into a standardized event log format.
- Discover the process model. The mining algorithm analyzes the sequence of activities across all cases and constructs a process map. It shows every path taken, every loop, every shortcut. A typical order-to-cash process with 10,000 orders might reveal 47 distinct paths�not the 2 or 3 your process diagram shows.
- Analyze bottlenecks. Overlay timing data on the process map. Identify which nodes have the longest waiting times, which paths are most common, which loops create the most rework. The process automation framework uses this analysis to prioritize which problems to solve first.
- Identify automation opportunities. Every bottleneck is an opportunity. Every handoff delay is a candidate for straight-through processing. Every exception pattern is a candidate for automated handling. The analysis produces a ranked list of automation targets by projected impact.
The key insight: process mining tells you where the leverage is. It replaces guesswork with measurement.
Process Mining vs. Traditional Consulting Audits
A traditional operations audit works like this: consultants interview stakeholders, review documentation, observe operations for a few days, and produce recommendations based on their expertise and what people tell them. The quality depends on whether people accurately describe their work�and whether the consultants have seen similar patterns before.
Process mining replaces "what people say" with "what the data shows." It is not subjective. It does not depend on memory or honesty. It shows exactly what happened in every case, across every system, over the entire period you have data for.
But that does not mean traditional audits are obsolete. They excel at context: understanding why a process runs the way it does, uncovering the political and organizational reasons behind process deviations, and building buy-in for change. The best approach combines both: use process mining to surface what is actually happening, use human expertise to understand why, and build solutions that address both the technical and human dimensions.
Workflow discovery bridges the two. It uses structured analysis methods borrowed from process mining but adapts them for environments where perfect data is not available. For most mid-market organizations, workflow discovery delivers 80% of the insight at 20% of the cost.
From Discovery to Automation
The real value of process mining and workflow discovery is not the beautiful process map. The map is a means to an end. The end is operational transformation�building the systems that eliminate the friction you discovered.
TZIR's approach treats discovery and automation as a single pipeline:
- Discover. Use process mining or workflow discovery to map the real process and quantify every bottleneck.
- Design. Architect the target process�the one that would exist if every handoff were instant, every data movement were automatic, and every exception were handled by logic instead of humans.
- Build. Implement the target process as a background logic backplane. The backplane orchestrates the handoffs, enforces the rules, and handles the exceptions. Systems talk directly. Decisions happen in milliseconds. Humans focus on the work only humans can do.
- Measure. The backplane generates its own event data. Now you are running process mining on the automated process�creating a continuous improvement loop.
This is where the automation ROI compounds. The first pass eliminates the biggest bottlenecks. But because the backplane captures every transaction and every exception, each subsequent analysis reveals deeper optimization opportunities. The data entry error costs that seemed invisible become measurable and then eliminated.
A logistics company we worked with discovered through process mining that 23% of all shipments had at least one address correction cycle. Each correction cost in labor and in carrier fees. The total: .2 million per year across 55,000 shipments. The root cause: sales reps entering addresses into a CRM that did not validate address format at point of entry. The fix: a three-line validation rule on the CRM form. Total implementation time: 45 minutes.
That is the pattern. The discovery surfaces the problem. The backplane eliminates it. The measurement confirms it.
Getting Started
Three approaches, depending on your data maturity:
Full Process Mining
Best for organizations with mature systems that generate clean event logs�ERP systems, CRM platforms, ticketing systems, workflow engines. Requires structured data with case IDs, activity names, and timestamps. The output is quantitative, precise, and comprehensive. Implementation timeline: 4-8 weeks for initial discovery.
Workflow Discovery
Best for organizations whose processes run across spreadsheets, email, and legacy systems. No perfect data required. Combines interviews, observation, and partial log analysis. Faster and cheaper�2-3 weeks for initial results�but less precise. Sufficient for identifying the top 80% of improvement opportunities.
Hybrid Approach
Start with workflow discovery to identify the highest-impact areas and build organizational buy-in. Then apply full process mining to those targeted processes. This minimizes upfront investment while ensuring you get the precision you need where it matters most.
The important thing is to start. The cost of not knowing what your operations actually look like is far higher than the cost of finding out. Every day you run blind is a day of hidden costs compounding�of approvals waiting, of errors propagating, of handoffs slowing everything down.
Process mining and workflow discovery turn the invisible into the visible. And once it is visible, you can build the systems that make it better.